Improve SEO With a Sitemap.xml & Robots.txt - A Guide

in Web Dev
Yesterday, I posted how to get an A+ in Mozilla's Observator security audit tool. The security auditing tools also revealed my site was missing a robots.txt file. With this PR, a proper robots.txt file is added to blogthedata.com!
The robots.txt file tells website spiders (also known as crawlers) which pages they may visit. It further communicates which urls are relevant and how often they update. I initially thought spiders were bad, but it’s more accurate to say that some spiders are naughty and some are nice. I guess that's true in real life, too!
One important spider to be aware of is Googlebot. If Googlebot never makes it to your website, you won't show up in Google search results AT ALL! Check this Google article for more info on how spiders are so important for Google Search.
Spiders will look for the following within a robots.txt file:
1 - Your web application's site map
2 - Directives on allowed/disallowed routes
So what is a sitemap, anyway?
A site map or sitemap is a list of pages of a web site.
Structured listings of a site's page help with search engine optimization, providing a link for web crawlers such as search engines to follow. Site maps also help users with site navigation by providing an overview of a site's content in a single glance.
- MDN
Django includes site maps as out of the box functionality. Here’s a great tutorial on implementing site maps in a Django app. For blogthedata.com, I added the following site maps:
- The About Page
- The Roadmap Page
- All Post URLs
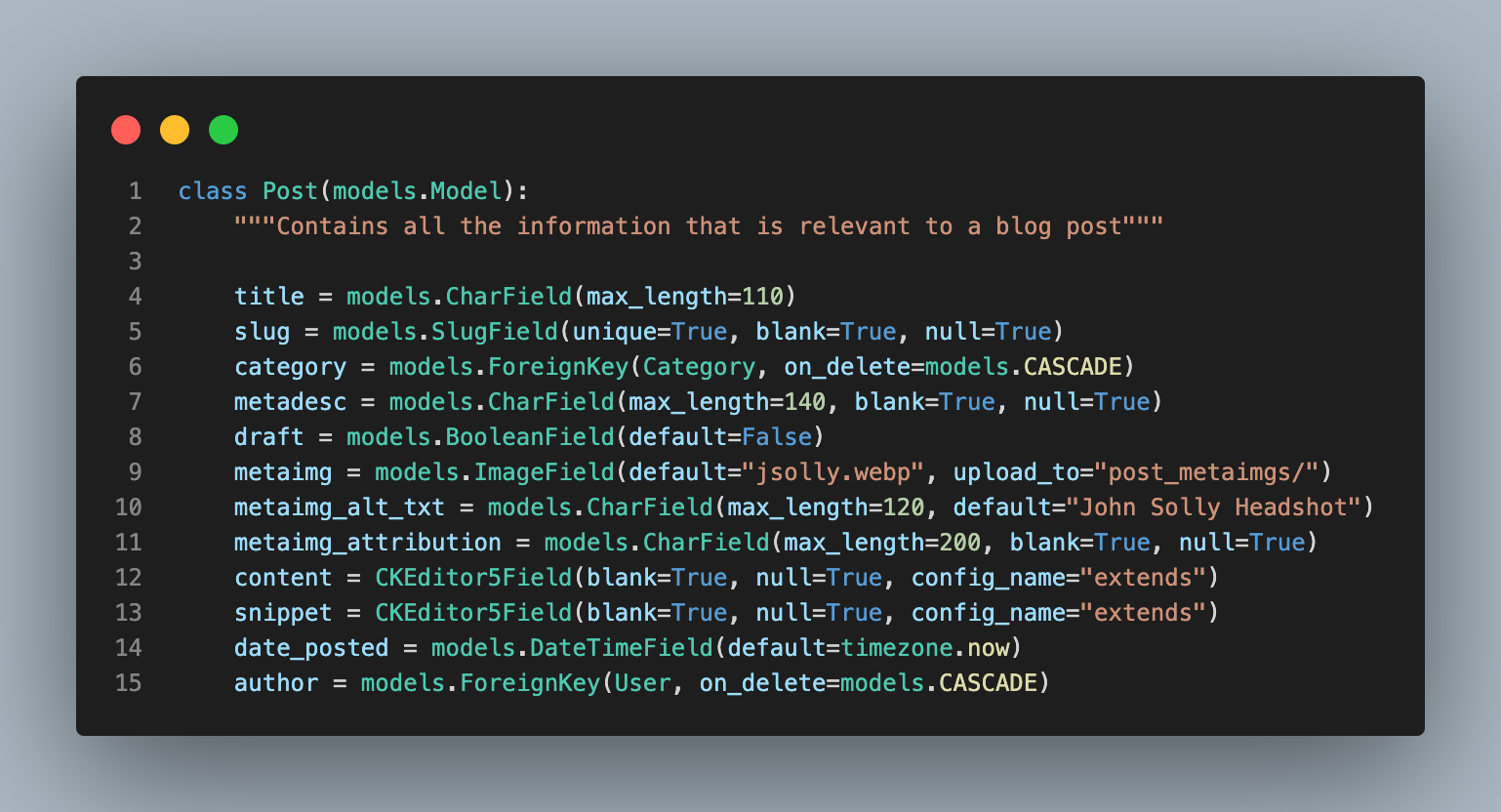
Here is a snippet of my PostSiteMap.
class PostSitemap(Sitemap):
changefreq = "weekly"
priority = 0.9
def items(self):
return Post.objects.all()
def lastmod(self, obj):
return obj.date_posted
#def location() Django uses get_absolute_url() by default, so no need to define the locationThe changefreq tells spiders how often to check the content for updates. My current implementation is not perfect because every post has a change frequency of 'weekly' when, in reality, posts do not modify once published.
A future enhancement might be to add my category pages (/site_updates, /life_advice) to the site map since they regularly update with new posts.
The priority property tells the spider how important the content is to a visitor. Not all pages are created equal!
You should have separate site maps for different pages because not every route updates as frequently. My about page, for example, has a change frequency of 'Monthly.'
class StaticSitemap(Sitemap):
changefreq = "monthly"
priority = 0.5
def items(self):
return ['blog-about']
def location(self, item):
return reverse(item)After adding my sitemap, I went into Google Search Console and submitted my sitemap url. Google successfully parsed my sitemap and found 33 paths! That should be all of my current blog posts + /about and /roadmap!
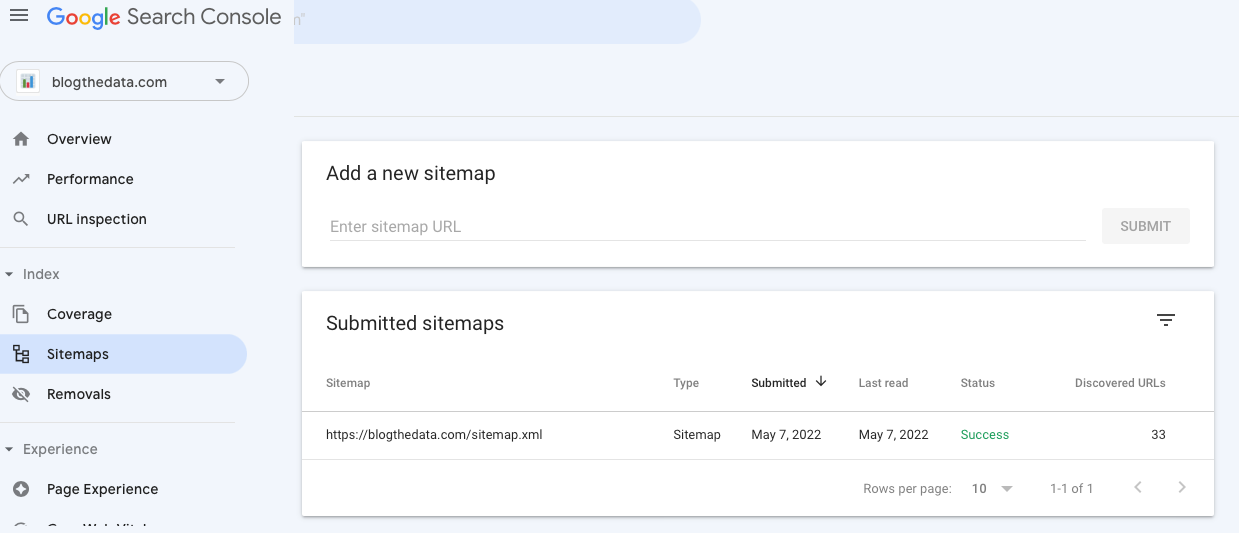
After adding site maps for all the relevant pages, you'll want to incorporate this into a robots.txt file. You can see my robots file here. I include the sitemap url so the spider knows where to go to learn more about blogthedata.com
The second portion of the robots.txt file is including directives instructing spiders which pages are 'off limits.' I've included a single route, /admin. This is the page I used to administer my site and I would rather it not get indexed and show up in Google search!!
In conclusion, having a sitemap.xml + robots.txt file is important for making sure your site gets indexed by crawlers such as the Googlebot. It tells the spiders which pages you want to turn up in search results as well as how often pages update.
Add this functionality to improve your SEO! 🕷
Comments
- No comments yet.



Related Posts
Implementing Anonymous Likes and Views in Django - A Guide
 2 min read
2 min readLearn to implement anonymous likes and views in Django with a step-by-step guide. Discover the best ways to track and record user engagement on your website.

Ahrefs Website Optimization: Fix Orphan Pages & Duplicate Content
7 min readAudit your website with Ahrefs to fix orphan pages and duplicate content for better UX, higher SEO, and improved performance.
0

Secure Website With security.txt: Fight Web Vulnerabilities
2 min readLearn how to create a security.txt file, understand its importance, and generate a GPG asymmetric key pair. FANG companies did it, so should you!
0

John Solly
A hands-on AI practitioner who transitioned to a CTO role to broaden my impact.
Most of my career has been dedicated to developing spatial systems at Esri, startups, and federal agencies. Currently, I lead technology strategy for Leidos' Health IT division, supporting agencies such as SSA, VA, and HHS.
My primary focus is the convergence of spatial computing and AI, enabling machines to interpret the physical world and applying these capabilities to meaningful missions.
Please reach out if you are interested in spatial systems or advancing AI within the federal government.
0