Eliminating Duplicate Pages With HTMX Infinite Scrolling

in Web Dev
Last updated:
Note
Hey!
Since this blogpost was written, I created a new and improved way to do infinite scrolling. Check out this YouTube Video to see the latest implementation.
Legacy Implementation
Htmx superpowers your html, allowing it to do things you would typically have to do in JavaScript. After discovering issues with duplicate pages due to my pagination implementation, I removed all the duplication with infinite scroll!
Luckily, I came across an excellent youtube video by bugBytes who walks you through how to pull off infinite scroll with htmx.
I won't bore you with all the details, but I will highlight how I adjusted the implementation to handle category pages.
In bugByte's example, he hardcodes the URL to fetch articles since he is only working with one view:
<div hx-get="{% film-list %}?page={{ page_obj.number|add:1 }}" hx-trigger="revealed" hx-swap="afterend" hx-target="this">
In my case, posts can come from multiple views. I modified the request to reference a url variable I passed within the view to support more than one view. Notice I replace film-list with url.
<div hx-get="{{ url }}?page={{ page_obj.number|add:1 }}" hx-trigger="revealed" hx-swap="afterend" hx-target="this">
Within each view, I pass the current path into the template as a context variable:
class CategoryView(ListView):
...
def get_context_data(self, *args, **kwargs):
...
context["url"] = self.request.path
return contextThis way, the template is always fetching the correct url!
Conclusion
After running into issues with duplicate content with my previous pagination implementation, I decided to use htmx to implement infinite scrolling. This resolved the duplication issue and introduced new functionality. I call that a win!
Comments



Related Posts
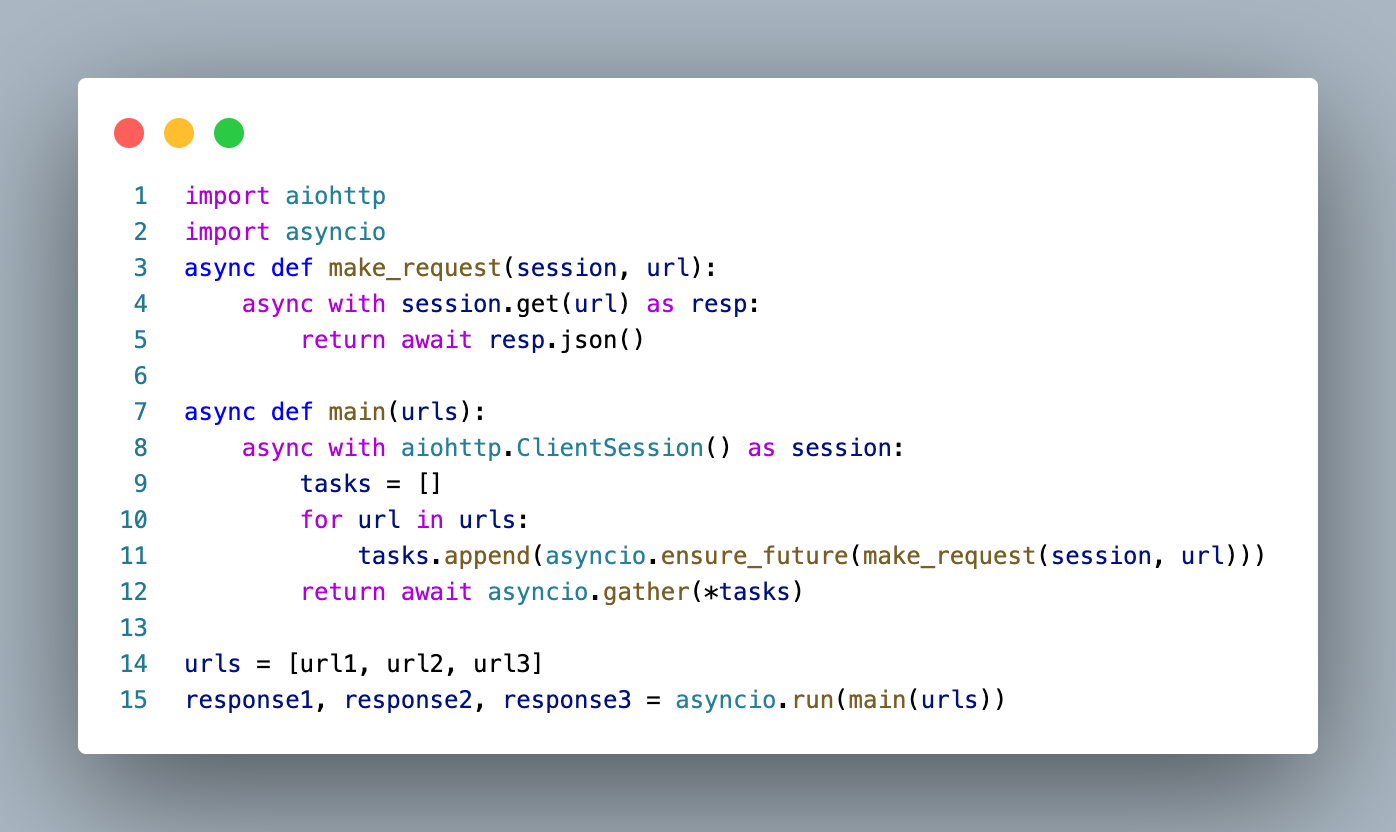
Speed Up REST Calls With AsyncIO | Get 388% Faster Results
 2 min read
2 min readUse asyncio to speed up your REST calls and get 388% faster results. Learn how to make multiple requests without waiting for each response.
0
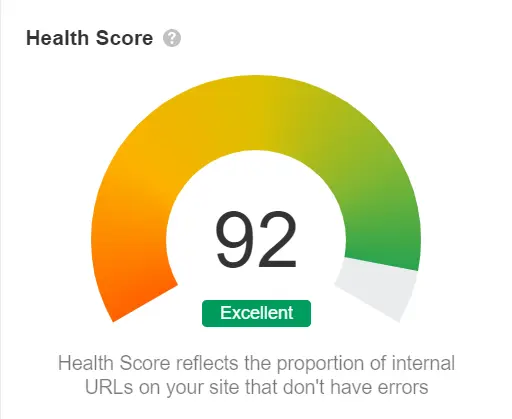
Improving Website Health With Ahrefs: A Step-by-Step Guide
2 min readImprove website's health score with Ahrefs and eliminate duplicate pages. Tips on fixing common issues and implementing new features.
0

Ahrefs Website Optimization: Fix Orphan Pages & Duplicate Content
7 min readAudit your website with Ahrefs to fix orphan pages and duplicate content for better UX, higher SEO, and improved performance.
0

John Solly
A hands-on AI practitioner who transitioned to a CTO role to broaden my impact.
Most of my career has been dedicated to developing spatial systems at Esri, startups, and federal agencies. Currently, I lead technology strategy for Leidos' Health IT division, supporting agencies such as SSA, VA, and HHS.
My primary focus is the convergence of spatial computing and AI, enabling machines to interpret the physical world and applying these capabilities to meaningful missions.
Please reach out if you are interested in spatial systems or advancing AI within the federal government.
I have faced issues with infinix scrolling while using HTMX.
I'm going to try this out!