Find the Optimal QA to Developer Ratio: Data-Driven Hiring Decisions
in Productivity
Recently came across a Stack Overflow thread discussing the ideal QA to Developer ratio for software development teams. According to the commenters, dev teams can range from no manual testing at all to a 1:1 ratio of dev to QA. My first thought was:
"Can we find a way to estimate how many QA engineers are needed based on a set of criteria that can be measured in any software project?"
After scanning the thread and reviewing a few other resources, I noticed patterns in how people justified more/less QA. Here are the variables I extracted:
Number of Developers - Self-explanatory
Number of lines of code - A naïve way to estimate code complexity and application size
Danger of Failure - How nasty would a bug be if introduced? A frustrating day at the office or lives lost?
Team Maturity - How experienced are the team with each other and development? A group of new grads or a seasoned development team working together for many years?
Degree of Change in Codebase - How volatile is the development effort? Is the product in beta and still has many moving pieces, or is it a mature product with predictable development?
Leverage existing libraries - If you're building an application that relies on 3rd party code, you won't need to invest as much time testing because the codebases you are leveraging have hopefully already been tested.
Amount of unit testing - How much unit test coverage is there? None, 100%?
I experimented with these parameters in Google Sheets using RANDBETWEEN( ) to input numbers like Lines of Code or Number of Developers. Then I used my judgment to estimate the number of QA engineers needed for a project.

With ~200 rows manually classified, I brought this up with my friend Aviv, who thought we could fit a model to the dataset to predict the number of QA Engineers needed for any situation. After importing the data into a Jupyter notebook, he trained a model using TensorFlow and exported the results to CSV,
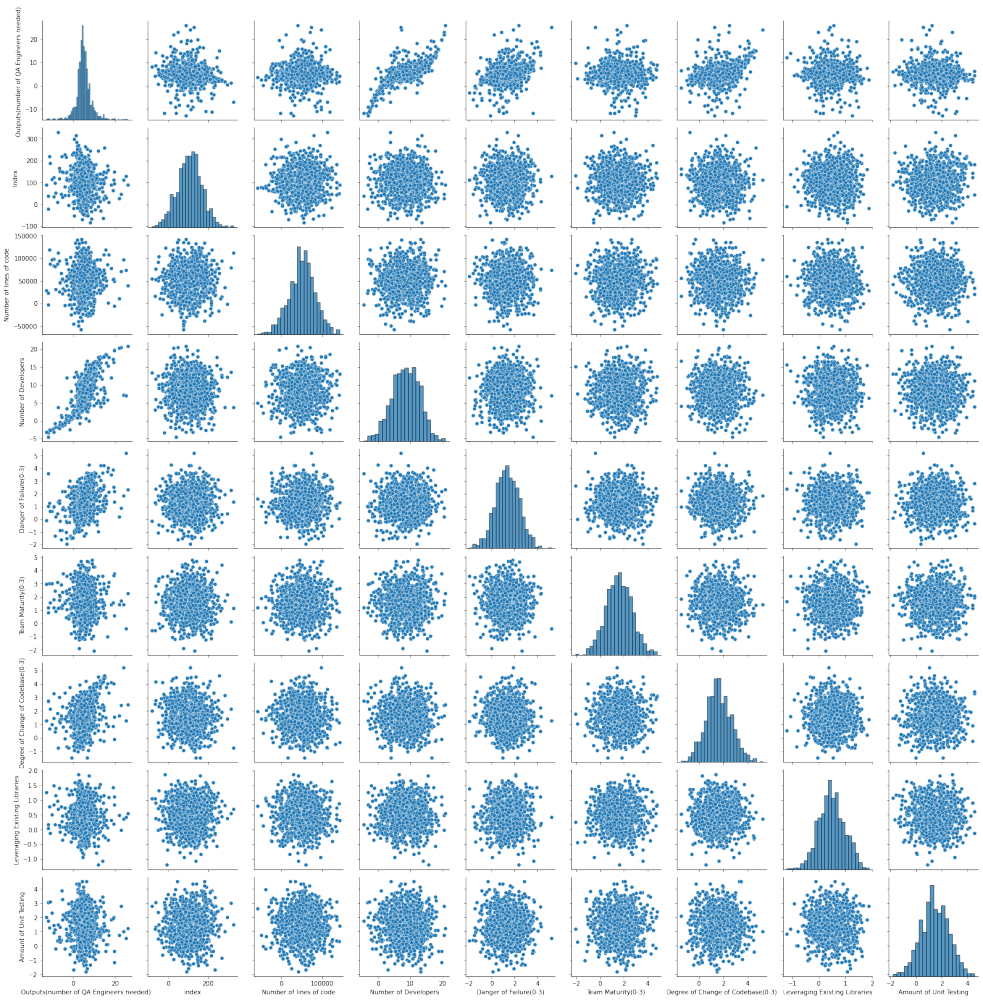
Here's a pair plot of the model's output. You can see the full report included in the notebook linked above.
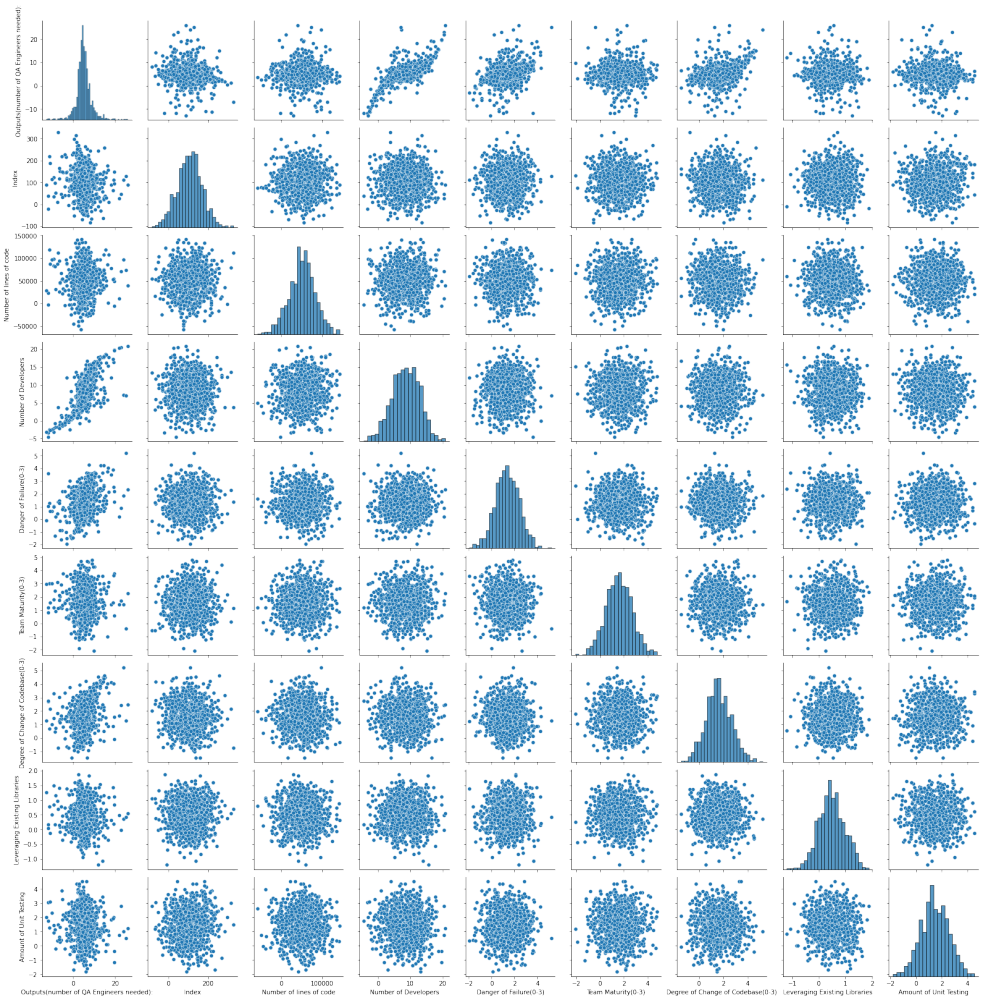
The model correctly discovered that when I manually labeled Number of QA Engineers needed, I mainly leveraged Number of Developers, Danger of Failure, and Degree of change in Codebase.
Conclusions
This was an initial attempt to explore whether QA Engineer hiring decisions could be data-driven. I wouldn't put too much weight into the final model, but it was a fun learning exercise! If I wanted to take this work further, I would dive deeper into the variables and devise a way to weigh each appropriately. I would also incorporate the whole QA testing strategy, including hiring SDETS (Software Developers in Test), offshore QA resources, and other 3rd party testing teams.
What do you think? Let me know in the comments 😁
Comments
- No comments yet.



Related Posts
Implementing Anonymous Likes and Views in Django - A Guide
 2 min read
2 min readLearn to implement anonymous likes and views in Django with a step-by-step guide. Discover the best ways to track and record user engagement on your website.
Adding CI to Your Project: Setting Up Github Actions for Blogthedata
4 min readLearn how to add a CI workflow to your project with Github Actions. A step-by-step guide to test, lint, and deploy code with Github Actions.
0
Boost Page Speed: Minification and Compression for Static Assets
3 min readBoost Your Website's Speed: How Compression and Minification Can Help You Reduce Your Payload Size by Up to 40%, For a Faster, More Responsive Website.
0

John Solly
Hi, I'm John, a Software Engineer with a decade of experience building, deploying, and maintaining cloud-native geospatial solutions. I currently serve as a senior software engineer at HazardHub (A Guidewire Offering), where I work on a variety of infrastructure and application development projects.
Throughout my career, I've built applications on platforms like Esri and Mapbox while also leveraging open-source GIS technologies such as OpenLayers, GeoServer, and GDAL. This blog is where I share useful articles with the GeoDev community. Check out my portfolio to see my latest work!
0