Why Cosine Similarity Beats Tags for Blog Organization
in Web Dev
Last updated:
Cosine Similarity > Tags
Organizing blog posts efficiently is crucial for enhancing user experience and ensuring readers can easily find related content. Traditionally, this has been achieved through tagging systems, where each post is assigned relevant tags that users can click to find related posts. While this method is simple and easy to implement, it comes with its own set of challenges. Tags can often be too broad or too narrow, and managing them effectively can become cumbersome. In this blog post, I explore an alternative approach that leverages large language models and similarity scores to automate finding and displaying related posts, eliminating the need for traditional tagging.
Why Tags Suck
My two gripes with tags are that it's hard to develop good tags that effectively separate posts. If I create a 'productivity' category, it might be too broad (too many posts are tagged) or too narrow (not enough posts are tagged). It's also a nightmare figuring out how many tags I should have and which ones should be attached to new posts.
I wanted to eliminate tags entirely and rely on a combination of large categories and something intelligent enough to determine which blog posts were related. This would allow me to do this automatically without any extra overhead.
Large language models had just started gaining popularity, and the RAG workflow closely resembled what I had sought. I wanted to know which posts were more related than others and use the similarity score to rank them.
Moving Beyond Tags
The workflow I came up with compares each of my blog posts to every other post. This runs in O(n²) time, but since I only have 100 blog posts, it's not a big deal.
Here's how I did it:
Step 1 - Create a Django Class for keeping track of the post similarities
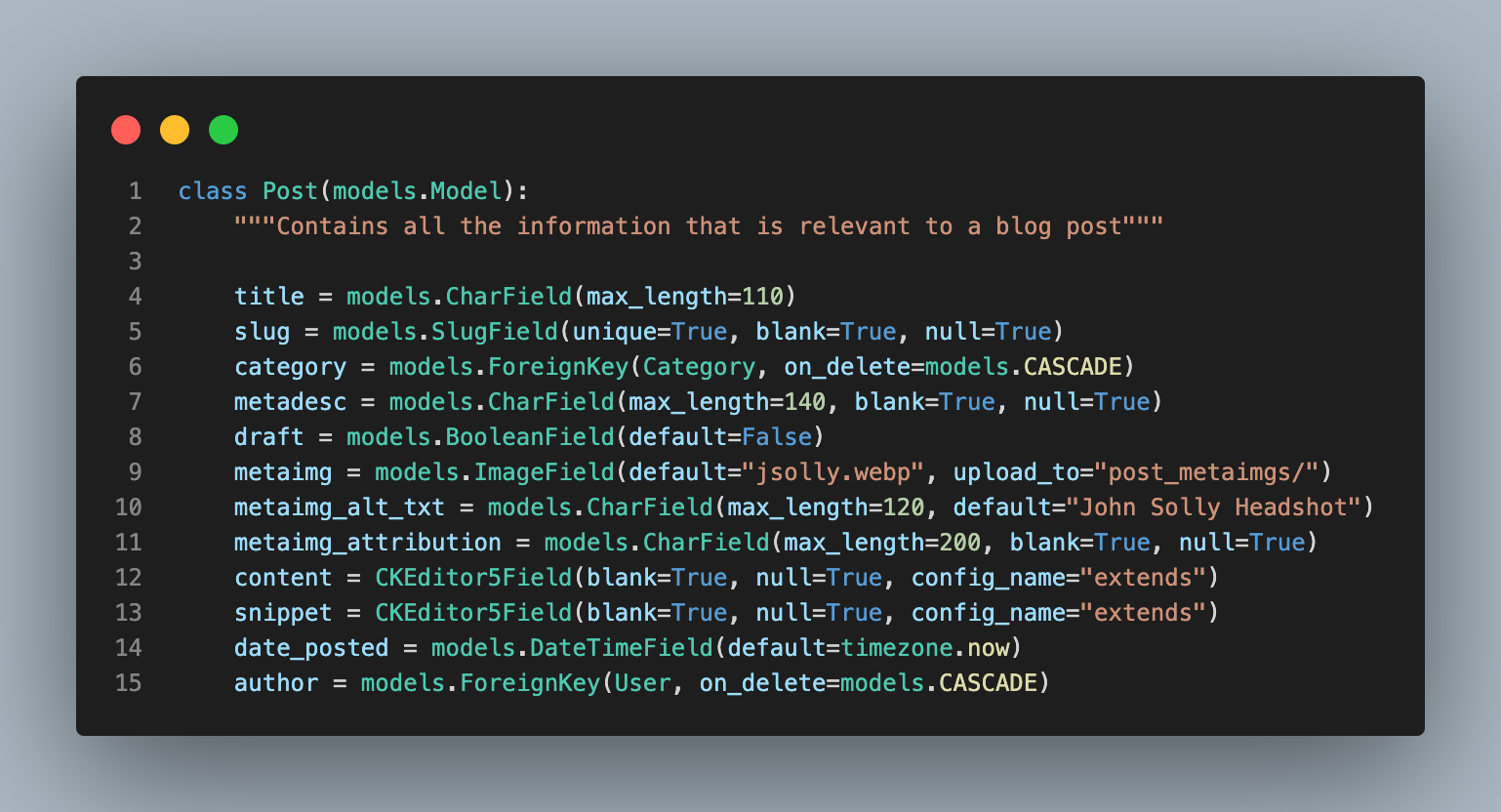
class Similarity(models.Model):
post1 = models.ForeignKey(
Post, related_name="similarities1", on_delete=models.CASCADE
)
post2 = models.ForeignKey(
Post, related_name="similarities2", on_delete=models.CASCADE
)
score = models.FloatField()
# Ensure that the same pair of posts can't be added twice
class Meta:
constraints = [
models.UniqueConstraint(fields=["post1", "post2"], name="unique_pair")
]Each instance of Similarity is a unique pair of blog posts. If you had four blog with ids, 1, 2, 3, 4, the similarity table would look something like this:
| id | post1_id | post2_id | score |
|---|---|---|---|
| 1 | 101 | 102 | 0.85 |
| 2 | 101 | 103 | 0.75 |
| 3 | 102 | 104 | 0.92 |
| 4 | 103 | 104 | 0.60 |
When viewing the post detail page for any one post, a function runs to fetch the top three posts that are most similar to the current post
def get_related_posts(self) -> models.QuerySet:
"""
Get the top 3 related posts based on the cosine similarities.
"""
return Post.objects.filter(
id__in=self.similarities1.order_by("-score").values_list(
"post2", flat=True
)[:3]
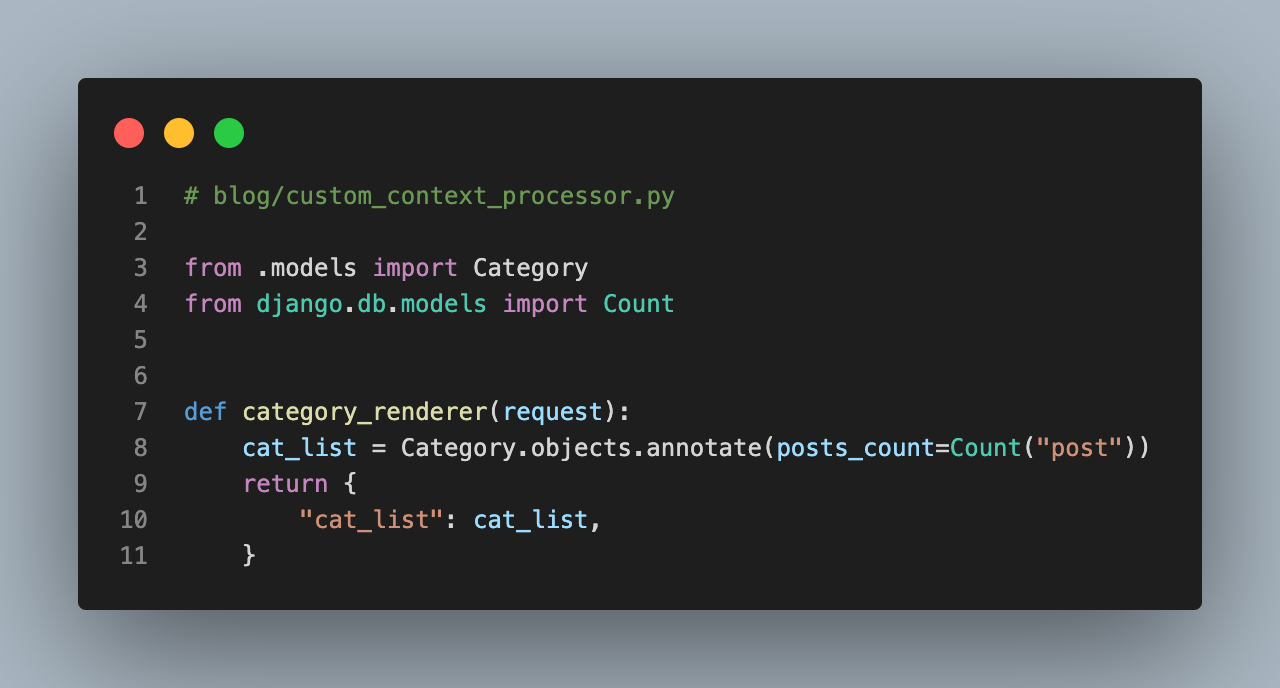
)When a post is saved, a signal in signals.py listens for the post-created event. It recalculates all the similarities since the newly saved post could relate to existing posts. Again, this would not scale, but with 100 posts, it runs in less than a second.
@receiver(post_save, sender=Post)
def trigger_similarity_computation(sender, instance, **kwargs):
compute_similarity(instance.id)compute_simularity is a pretty complex function, but the gist of it is that every post is compared pairwise to every other post using Cosine Similarity. If there are 100 posts, each post will have 99 cosine similarities. If you want to see the complete implementation, check out awesome-django-blog on GitHub!
Conclusion
Implementing an automated system to determine related blog posts based on similarity scores can significantly streamline content organization and improve user experience. We can ensure that readers are always presented with the most relevant content by utilizing a Django model to track post similarities and recalculating these scores whenever a new post is added. Although this approach may not scale well for larger blogs, it is highly effective for smaller sites with a manageable number of posts. This method reduces the overhead associated with manual tagging and provides a more intuitive and dynamic way to connect related content.
Comments
- No comments yet.



Related Posts
Implementing Anonymous Likes and Views in Django - A Guide
 2 min read
2 min readLearn to implement anonymous likes and views in Django with a step-by-step guide. Discover the best ways to track and record user engagement on your website.

Add Social Share Buttons to Your Blog Posts With OpenGraph Tags
5 min readAdd social share buttons to your blog posts with Twitter, LinkedIn, and Reddit. Get post previews to show correctly with Twitter meta tags and OpenGraph tags.
0
Django Context Processors and Multi-Stage Migrations: Lessons Learned
7 min readSometimes minor features need large technical lifts. How a small UI change pushed me to learn Django’s Context Processors and DB Migrations.
0

John Solly
Hi, I'm John, a Software Engineer with a decade of experience building, deploying, and maintaining cloud-native geospatial solutions. I currently serve as a senior software engineer at HazardHub (A Guidewire Offering), where I work on a variety of infrastructure and application development projects.
Throughout my career, I've built applications on platforms like Esri and Mapbox while also leveraging open-source GIS technologies such as OpenLayers, GeoServer, and GDAL. This blog is where I share useful articles with the GeoDev community. Check out my portfolio to see my latest work!
0